运行官方示例WordCount
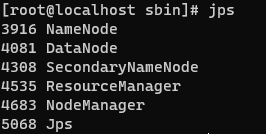
环境安装完成后输入jps确保有5+个进程:
本实验使用官方WordCount程序实现Java源码词语统计。
准备Java源码
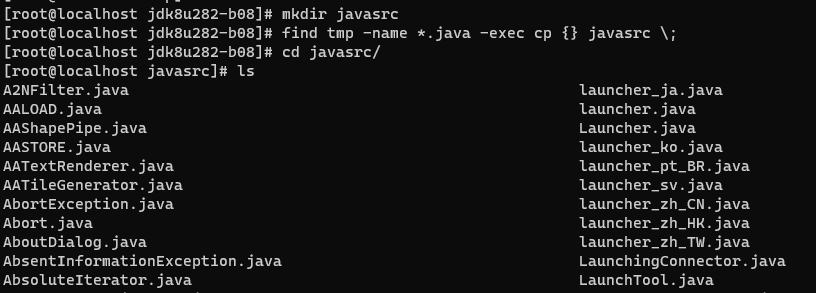
首先进入Java安装目录,找到src.zip,解压到tmp中
cd /opt/jdk8u282-b08/
unzip -d tmp src.zip
接着将tmp中的所有.java文件拷贝到javasrc目录下,需要先创建javasrc文件夹
mkdir javasrc
# 找到文件名匹配*.java的文件后执行 cp 命令复制文件。注意\;是-exec的结束标志
find tmp -name *.java -exec cp {} javasrc \;
上传文件至HDFS
由于Java源码大多为小文件,需要将这些文件合并成一个大文件。如果不这样做的话会由于io开销过大而导致运行时间过长。
此处使用appendToFile将本地的所有java文件上传到HDFS的input/data_file中
cd /opt/jdk8u282-b08
# 文件会上传到HDFS的/user/<login_user>/input/data_file中,
# 该目录如果不存在则会自动创建
hadoop fs -appendToFile javasrc/*.java input/data_file
hadoop fs -ls input
hadoop fs -tail input/data_file # 查看末尾1KB的内容

运行WordCount
官方示例文件在/opt/hadoop~/share/hadoop/mapreduce/hadoop-mapreduce-examples-~.jar中
hadoop jar命令用于执行jar文件,wordcount是例子的主类[?],input是输入文件所在目录,output是输出文件所在目录。output目录不能事先存在。
hadoop jar /opt/hadoop-2.9.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount input output
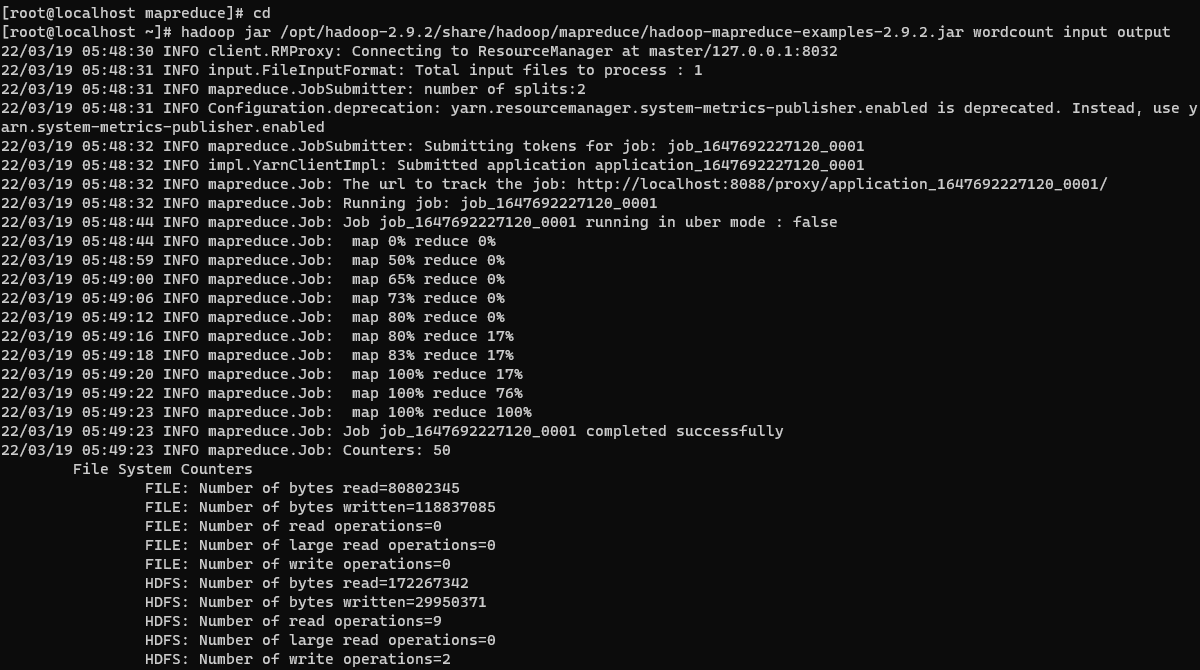
可以看到map和reduce操作是并行进行的
查看输出结果
查看HDFS中的output文件夹
hadoop fs -ls output

当运行成功后会在该文件下生成一个_SUCCESS文件,该文件长度为0,仅预示着成功输出了结果,其实际结果 存放在part-r-xxxxx文件中
查看结果的最后1KB
hadoop fs -tail output/part-r-00000
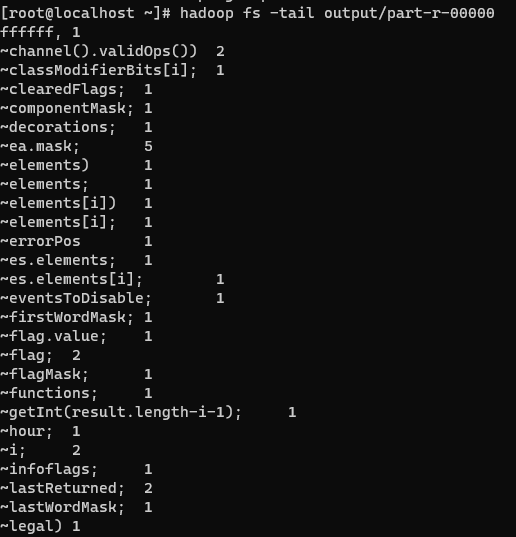
这些结果没有按照词频排序,需要进一步处理。
结果处理
首先将结果提取到本地
hadoop fs -get output

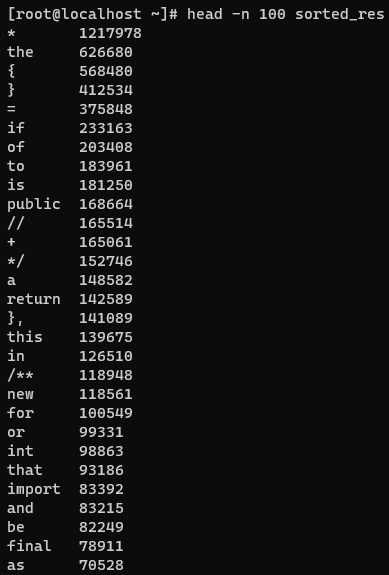
按照词频对结果降序排序,并将排序结果输出到sorted_res文件中。查看前100行数据
sort -t $'\t' -k2nr output/part-r-00000 >> sorted_res
head -n 100 sorted_res