分桶针对数据文件进行分解,分解成更容易管理的多个部分(细粒度)。好处有:
- 方便抽样:分桶后可以很方便的在数据集的一小部分上查询。
- 提高join查询效率
分桶是在表或者分区表的基础上进一步对表进行组织,分桶会对列值进行Hash,来决定放在哪个桶中。保证每个桶中都有数据,但桶中的数据条数不一定相等。
创建分桶表
使用clustered by 命令指定划分桶的列,使用into N buckets指定桶的个数
create table buck (id int, name string) clustered by(id) into 4 buckets row format delimited fields terminated by '\t';
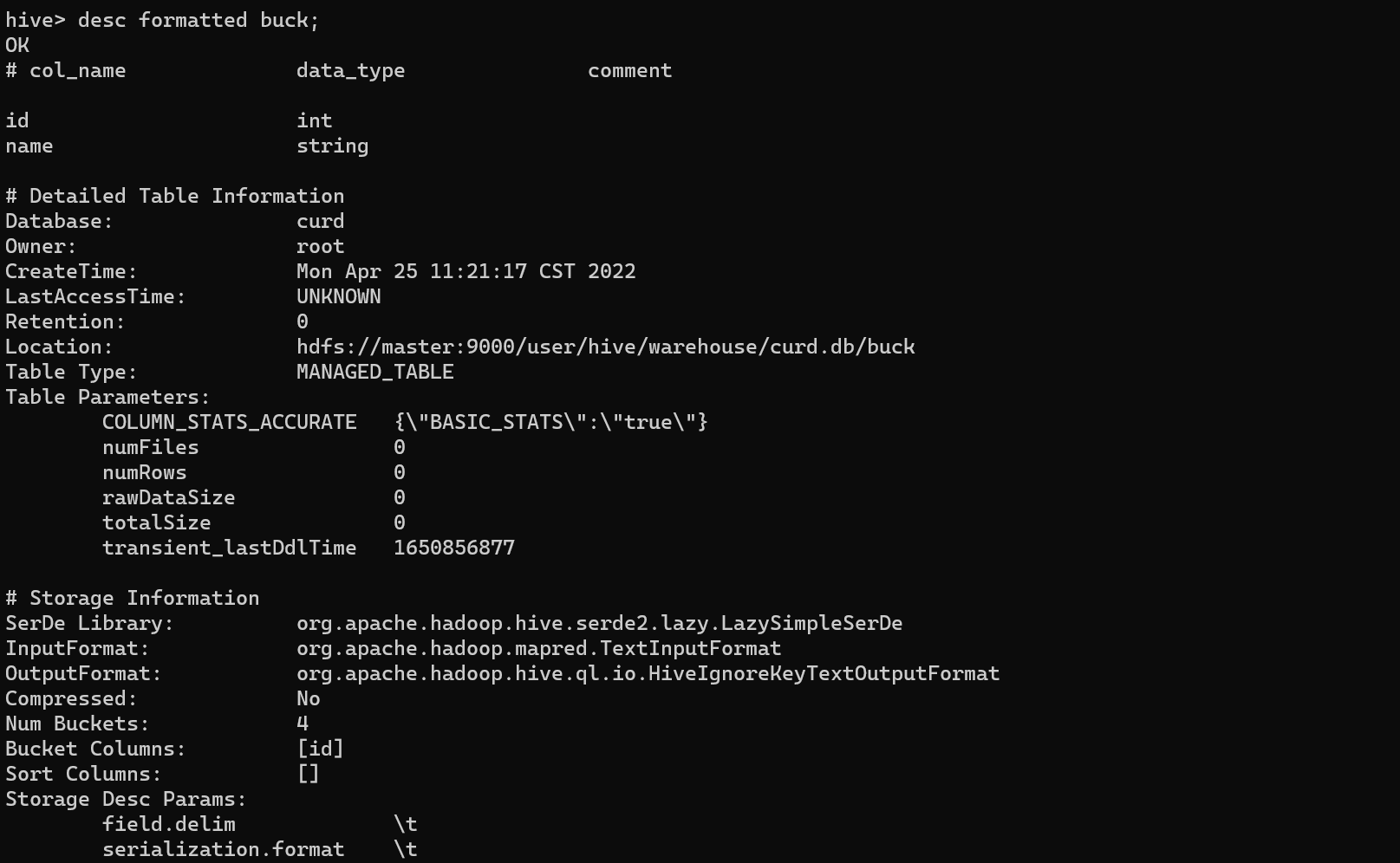 可以看到桶个数(Num Buckets)为4
可以看到桶个数(Num Buckets)为4
分桶表不能直接导入数据,需使用中间表。这里创建中间表
create table tmp (id int, name string) row format delimited fields terminated by '\t';
导入数据
首先设置Hive参数
set hive.strict.checks.bucketing=false;
在本地/root/buck.txt中有
1\taaa
2\tbbb
3\tccc
4\tddd
由于不能直接导入分桶表,所以首先应导入普通表
load data local inpath '/root/buck.txt' into table tmp;
接着清空分桶表中的数据
truncate table buck;
最后插入tmp中的数据到分桶表中
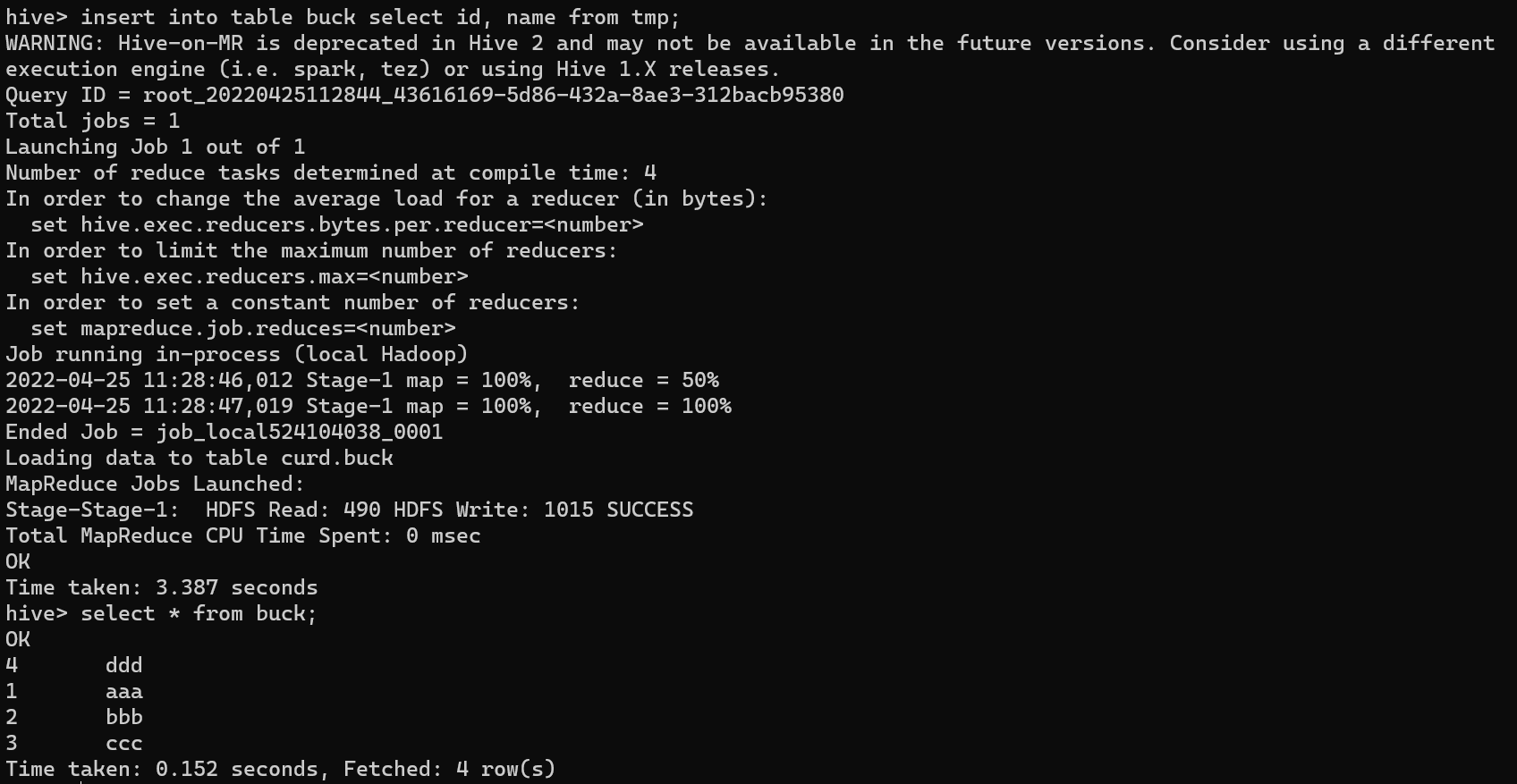
insert into table buck select id, name from tmp;
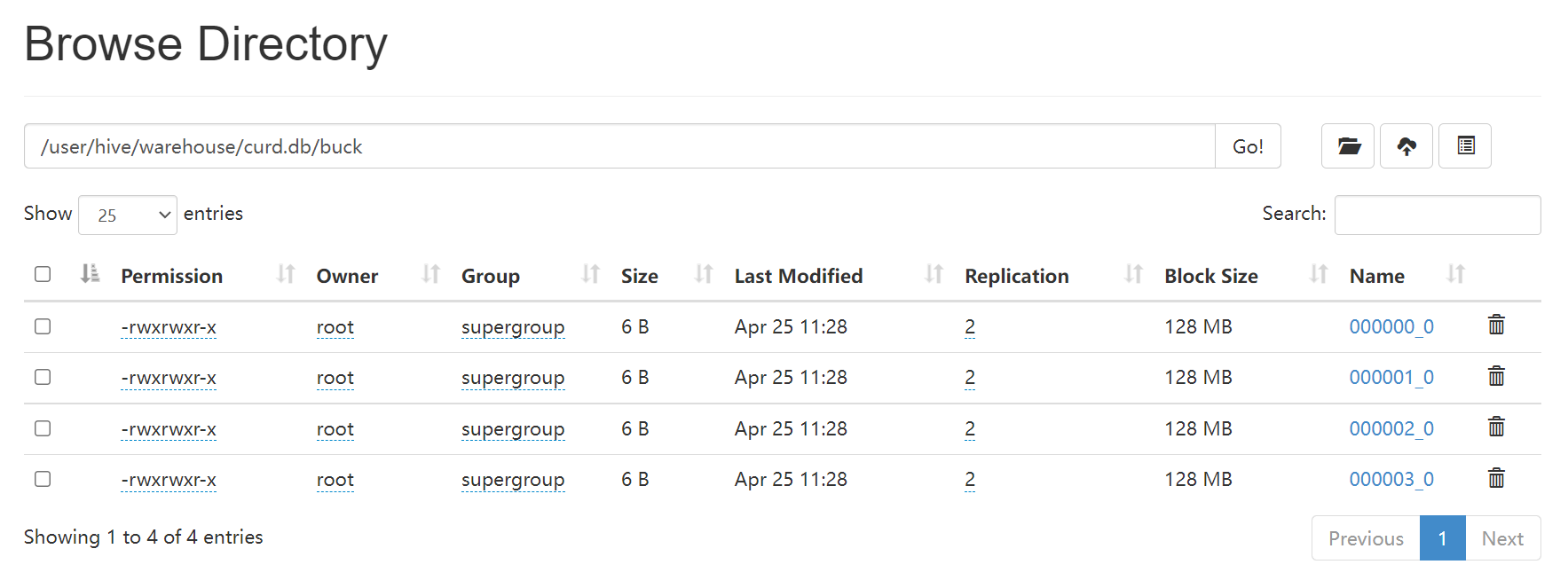
查看HDFS,可以看到buck下有4个文件,即分成了4个桶。
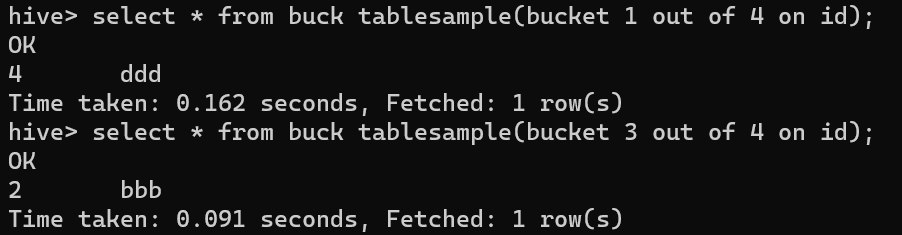
分桶抽样查询
使用tablesample对数据进行抽样
select * from buck tablesample(bucket 1 out of 4 on id);
select * from buck tablesample(bucket 3 out of 4 on id);