-
student表
id name 1 zhangsan 2 lisi 3 wangwu -
teacher表
id name 1 teacher_zhaoliu 2 teacher_wangqi
基本查询
全表查询
select * from student;
select * from teacher;
特定列查询
select id from student;
select name from teacher;
列别名
select id as a, name as b from student;
算数运算符:可以对结果集合进行算数运算以及位运算
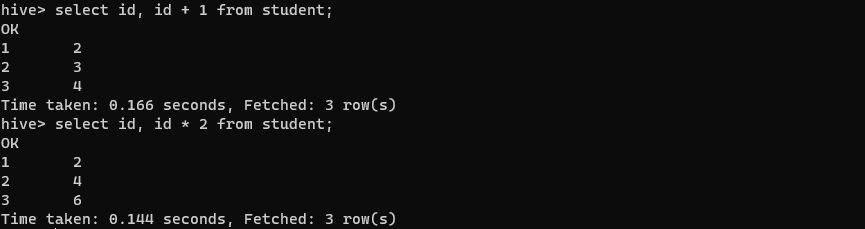
select id, id + 1 from student;
select id, id * 2 from student;
逻辑运算符: and or not
select id from student where id = 1 and name = 'zhangsan';
select id from student where id = 1 or id = 2;
select id from student where not id = 4;
常用函数
select max(id) from student; # 最大值
select min(id) from teacher; # 最小值
select count(*) from student; # 计数
select avg(id) from student; # 平均
限制结果行数,设置偏移量
select * from student limit 2;
select * from student limit 2 offset 1;
Where 条件
常用where
select * from student where id < 3;
select * from student where id = 2;
select * from student where id > 1;
between
select * from student where id between 1 and 3; # 1, 2, 3
is null
select * from student where id is null;
in: 查询是in括号内的条目
select * from student where id in(1, 3); # 1, 3
Like 通配
% 表示0个或n个字符
select name from student where name like 'zhang%';
_ 表示通配一个字符
select name from student where name like 'zhangsa_';
RLike可以通过正则来匹配
# 查找姓名中有字母n的
select name from student where name rlike '[n]'; # zhangsan, wangwu
Group by 分组统计
select id, avg(id) from student group by id;
having: 只能用于group by分组统计语句。
select id, avg(id) from student group by id having id > 1;
Join 连接
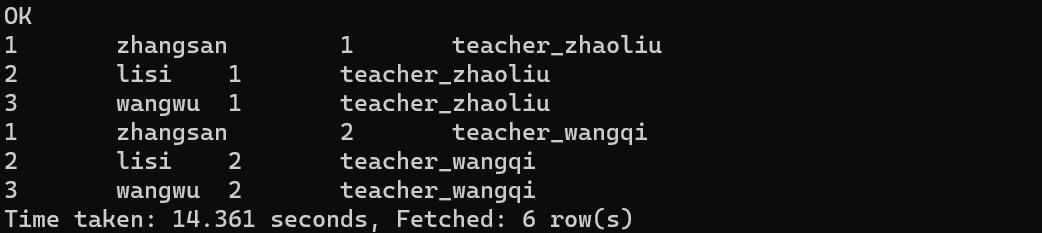
内连接,
# 找出student表和teacher表中id相同的id与name
select s.id, s.name, t.id, t.name from student as s join teacher as t on s.id = t.id;

左外连接: 返回join左边表中符合where子句的所有记录
select s.id, s.name, t.id, t.name from student as s LEFT join teacher as t on s.id = t.id;

右外连接: 返回join右边表中符合where子句的所有记录
select s.id, s.name, t.id, t.name from student as s RIGHT join teacher as t on s.id = t.id;

全外连接: 返回所有表中符合where语句条件的所有记录,如果有字段无符合条件的值,则用NULL代替
select s.id, s.name, t.id, t.name from student as s FULL join teacher as t on s.id = t.id;

笛卡尔积
select s.id, s.name, t.id, t.name from student as s, teacher as t;
 注:如果提示:
注:如果提示:
 则需要关闭严格模式
则需要关闭严格模式
set hive.strict.checks.cartesian.product=false;
set hive.mapred.mode=nonstrict;
排序
order by:对结果排序
select * from student order by name asc; # 名称升序
select * from student order by id desc; # id降序
select * from student order by name, id desc; # 多关键字降序
sort by:每个Reducer内部进行排序,但对最终结果集合来说不是排序
set mapreduce.job.reduces=2; # 设置两个reducer
# set mapreduce.job.reduces; # 查看reducer个数
select * from student sort by id desc;
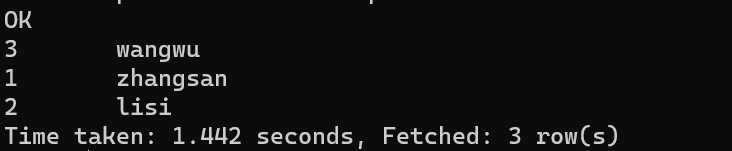 可以看到结果集并非降序
可以看到结果集并非降序
distribute by: 类似MapReduce中的partition,进行分区,需结合sort by使用
cluster by: 当distribute by和sort by字段相同时,可以使用cluster by
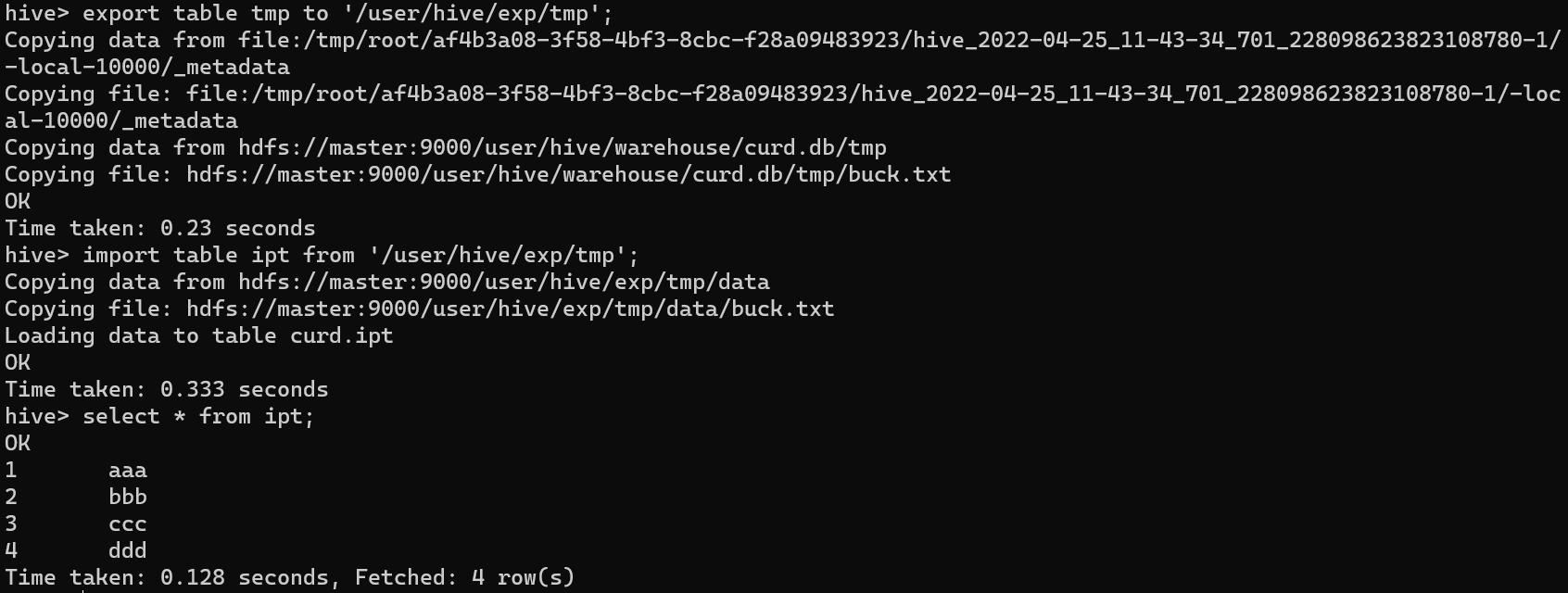
导出表至HDFS
export table tmp to '/user/hive/exp/tmp';
从HDFS导入表
导入的表不能事先存在
import table ipt from '/user/hive/exp/tmp';
# import external table exipt from '/user/hive/exp/tmp'; # 导入进外部表
select * from ipt;
从HDFS导入分区
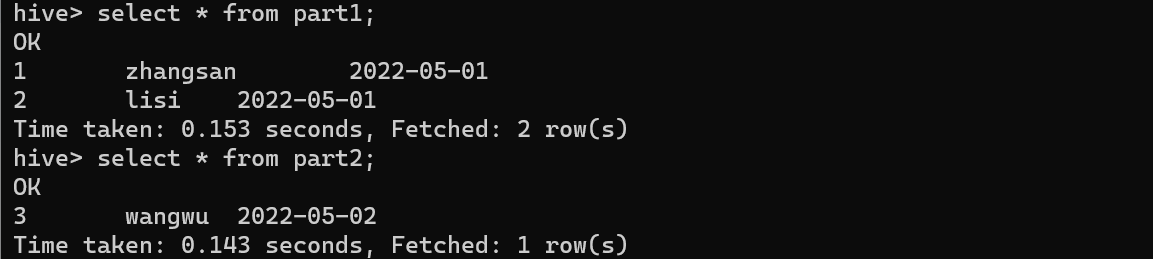
导出分区表
export table part to '/user/hive/exp/part';
导入分区
import table part1 partition(dt='2022-05-01') from '/user/hive/exp/part';
import table part2 partition(dt='2022-05-02') from '/user/hive/exp/part';
导出查询结果
将查询结果导出至本地
insert overwrite local directory '/root/exp' row format delimited fields terminated by '\t' select * from tmp;

将查询结果导出至HDFS(没有local)
insert overwrite directory '/user/hive/exp.txt' row format delimited fields terminated by '\t' select * from tmp;
将Hive Shell的查询结果保存到本地
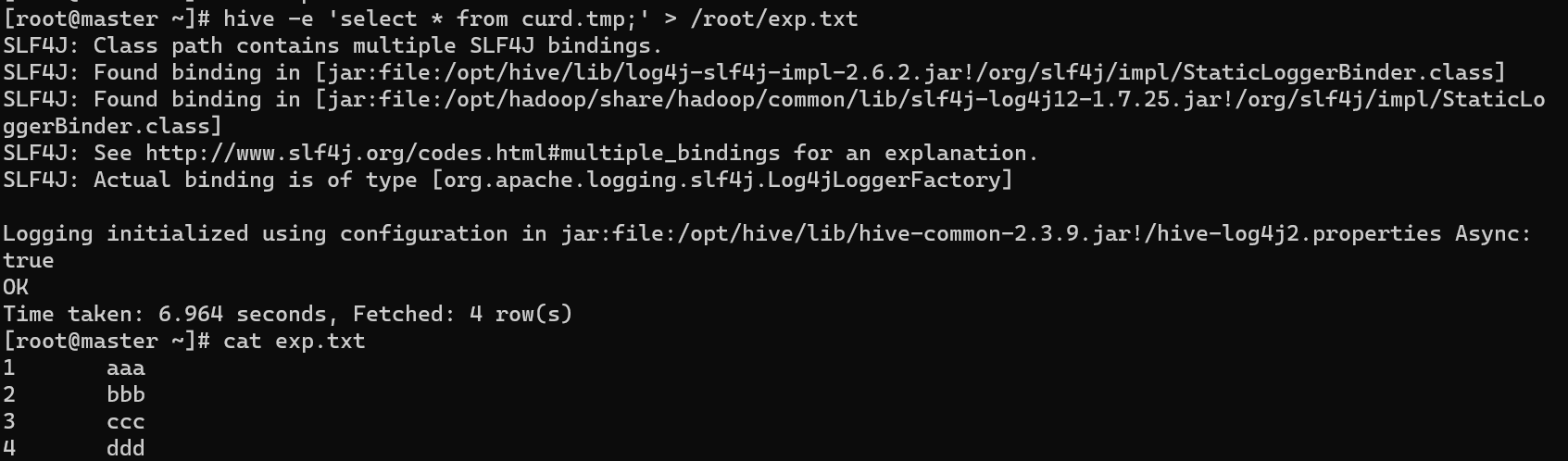
hive -e 'select * from curd.tmp;' > /root/exp.txt