Hive中的分区就是子目录(粗粒度),每个子目录包含了分区对应的列名和每一列的值,把大的数据集分割成小数据集。
分区表对应HDFS中的一个独立文件夹,该文件夹下存储了当前分区的所有数据文件。
在查询时使用where来指定分区,可提高查询效率。
创建分区表
使用partitioned bt 创建分区表,并使用dt作为分割分区的列名。
分割分区的列名越多分区的级数就越多,比如一个为一级分区,两个为二级分区。
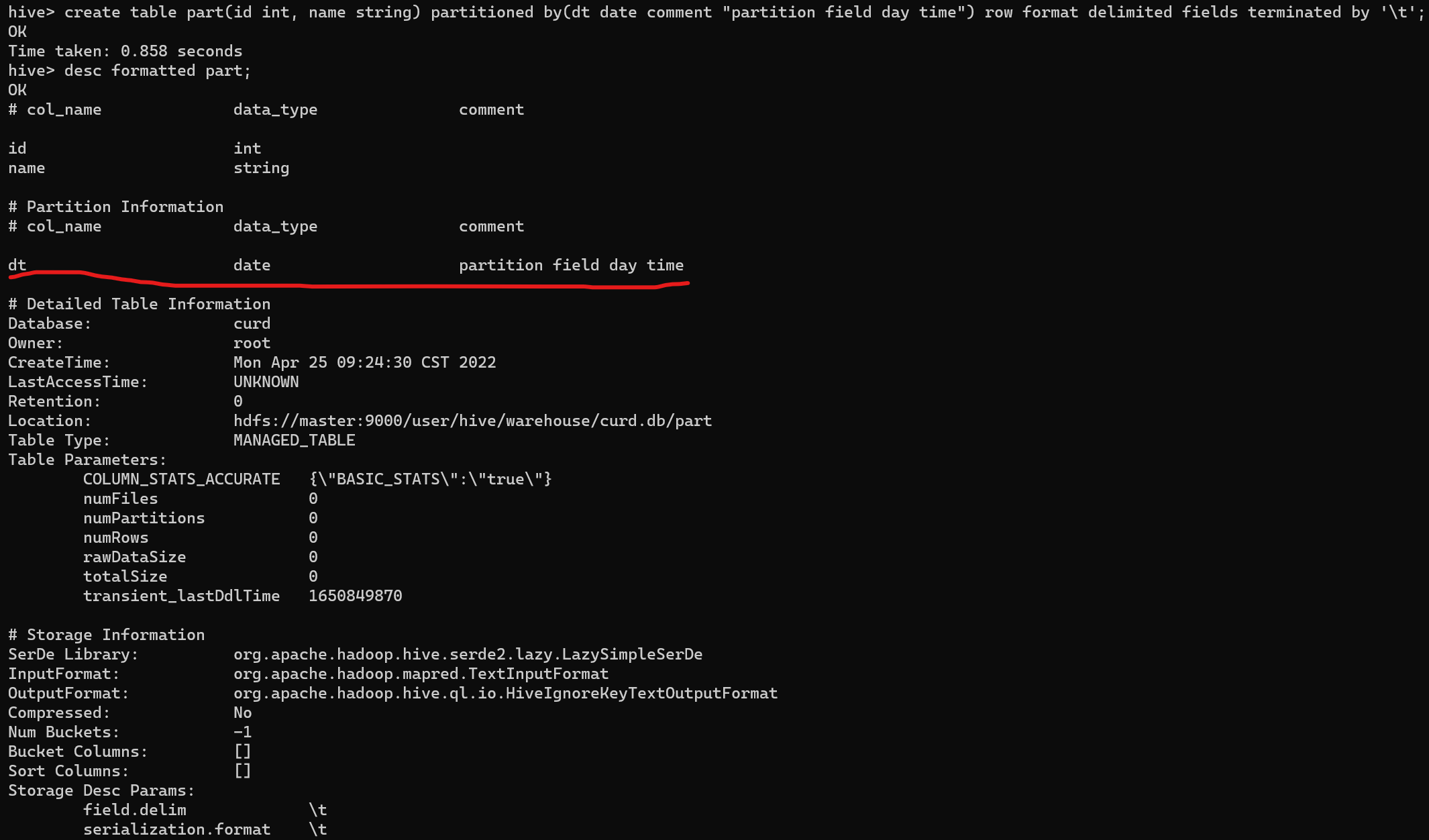
use curd;
create table part(id int, name string) partitioned by(dt date comment "partition field day time") row format delimited fields terminated by '\t';
添加分区
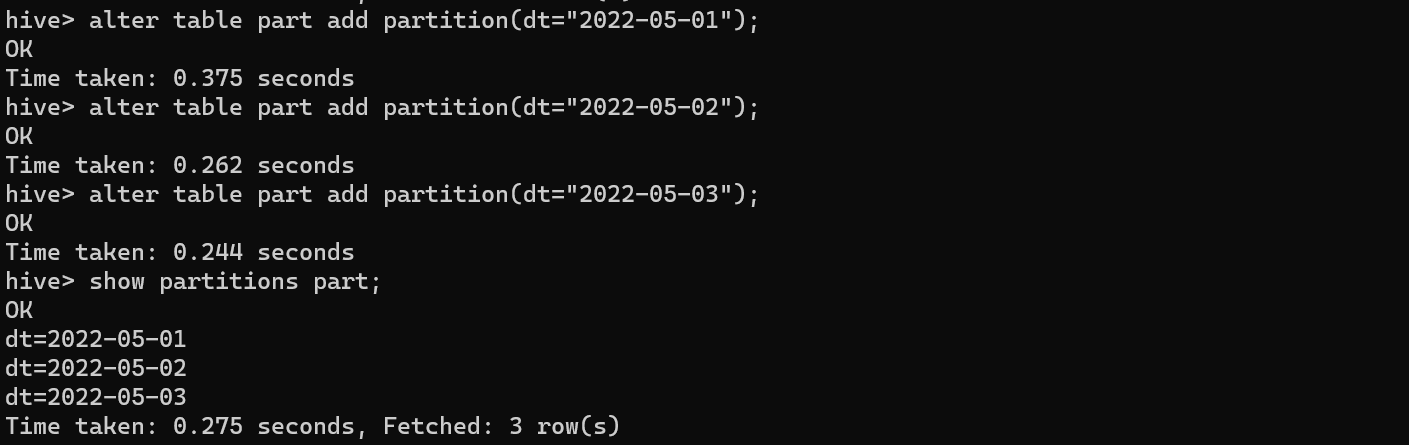
给分区表添加分区,区分 分区的列名为dt
alter table part add partition(dt="2022-05-01");
alter table part add partition(dt="2022-05-02");
alter table part add partition(dt="2022-05-03");
# 或者alter table part add partition(dt="2022-05-01") partition(dt="2022-05-02");
show partitions part; # 查看分区
导入数据
向分区中导入数据
在本地/root/中有三个文件: log01.txt,log02.txt,log03.txt
1\tzhangsan
2\tlisi
3\twangwu
4\tzhaoliu
导入数据:
load data local inpath '/root/log01.txt' into table part partition(dt='2022-05-01');
load data local inpath '/root/log02.txt' into table part partition(dt='2022-05-02');
load data local inpath '/root/log03.txt' into table part partition(dt='2022-05-03');
查询数据
查看所有数据
select * from part;

查看指定数据
select * from part where dt='2022-05-01';

select * from part where dt='2022-05-02' or dt='2022-05-03';

删除分区
alter table part drop partition(dt='2022-05-03');
修改分区表
重命名表
alter table part rename to new_part;
更新列
alter table part change id new_id int;
增加列
alter table part add columns (new_col string);
删除分区表
- 清空分区表 使用truncate命令
truncate table part;
- 删除分区表 使用drop命令
drop table part;